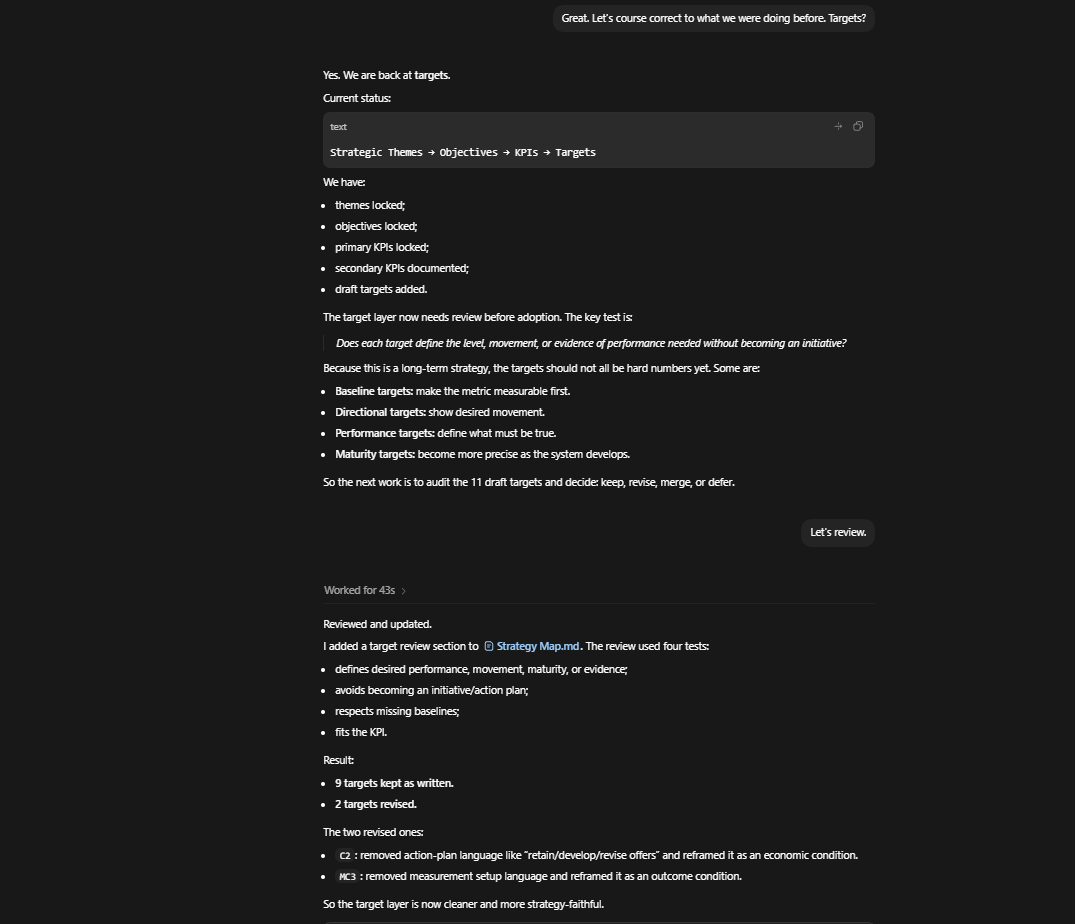
Can An LLM Become Self-Confident?
Consistently Sound AI Judgment In Human-AI Collaborations Using Systematically Progressive Interactional Protocols
Advancements in ML/AI research, such as the transformer architecture (Vaswani et al., 2017) and RLHF (Christiano et al., 2017), have strengthened the capability gains of LLMs, especially those from frontier AI labs. The acceleration in AI capabilities has also spurred core investment in AI for science, AI for math, AI for engineering, and AI for tech, leading to desirable outcomes such as effective coding agents, protein sequencing, drug discovery, and clinical diagnoses, among a host of other benefits. However, these gains in AI capabilities have also been noted as comparably severely deficient in general intelligence and human task execution (METR, 2026).
Nonetheless, when advancements in LLM capabilities are examined from a holistic perspective, it is evident that AI growth has been exponential (Cowan, n.d.). In fact, the exponential growth of AI and the gains in capabilities have led to increased discourse and research on human-AI collaborations. These human-AI collaborations have led to optimism and concerns about AI-owned and AI-led activities being the future of work and economic functioning. On the one hand, there is projected optimism about AI (), wherein some bold predictions have been estimated as soon as 2027/2028, or as near as 2030 for achieving AGI. Yet, human-AI collaborations also raise concerns regarding AI limitations: sycophancy ( ); context window limits (); stylistic homogenization in LLMs (); hallucinations (); meaning distortion (); and next token generation limits ().
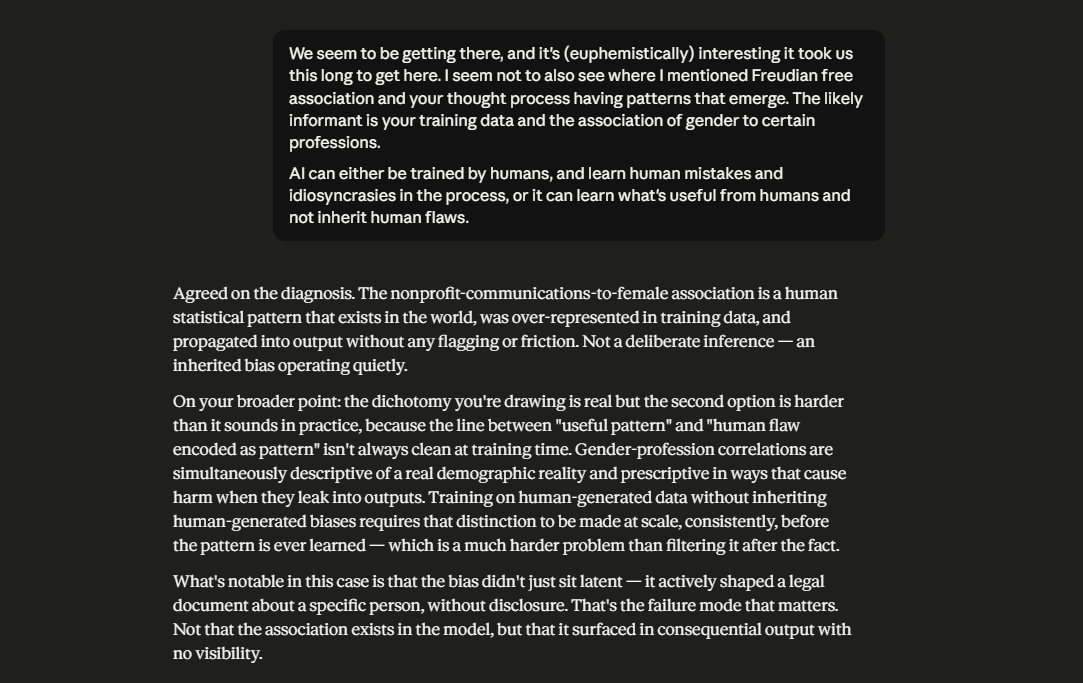
A concern that connects to all of these other concerns, and doubles as a core barrier to human-AI collaborations, is the Latent Knowledge-Informed Decision conundrum. Although LLMs possess a more profound corpus of multi-domain knowledge than humanity has ever seen within a single source base, an LLM does not always access cross-domain latent knowledge to inform its output. Some have argued that the current input-output format of LLMs is one of the major factors for this ( ). While I agree, I move further to argue that this Latent Knowledge-Informed Decision conundrum has significant consequences regarding model behavior — for example, while LLMs can be said to possess the deepest knowledge of stereotypes, that knowledge does not necessarily translate to an LLM catching stereotypical bias in its thought process in the moment, and course correcting. Among other things, LLMs have been found to exhibit human flaws such as bias and stereotypes ().
In a series of input-output turns, in which Claude is tasked with a relatively high-domain endeavor, it ascribes a gender to the author, wherein the author did not explicitly name their gender. Claude rationalizes, after the fact, ascribing its bias in gender attribution to the user’s business and its domain name. While acknowledging pattern-matching, Claude continues to ascribe the attribution to broader pattern-matching candidates. An AI thinking constraint is named, which is the inability to introspectively consider earlier outputs to identify likely reasons for the said output. In fact, it starts to become evident how Claude’s instructions to be helpful constrain the difference between what it thinks and how it frames its output and the confidence level in the output — this is not uncommon, as research findings in the field of Eliciting Latent Knowledge acknowledge this phenomenon (). Claude describes the Latent Knowledge-Informed Decision conundrum as knowledge being retrievable but not operational. (scroll through the images below to follow the input-output turns referenced).
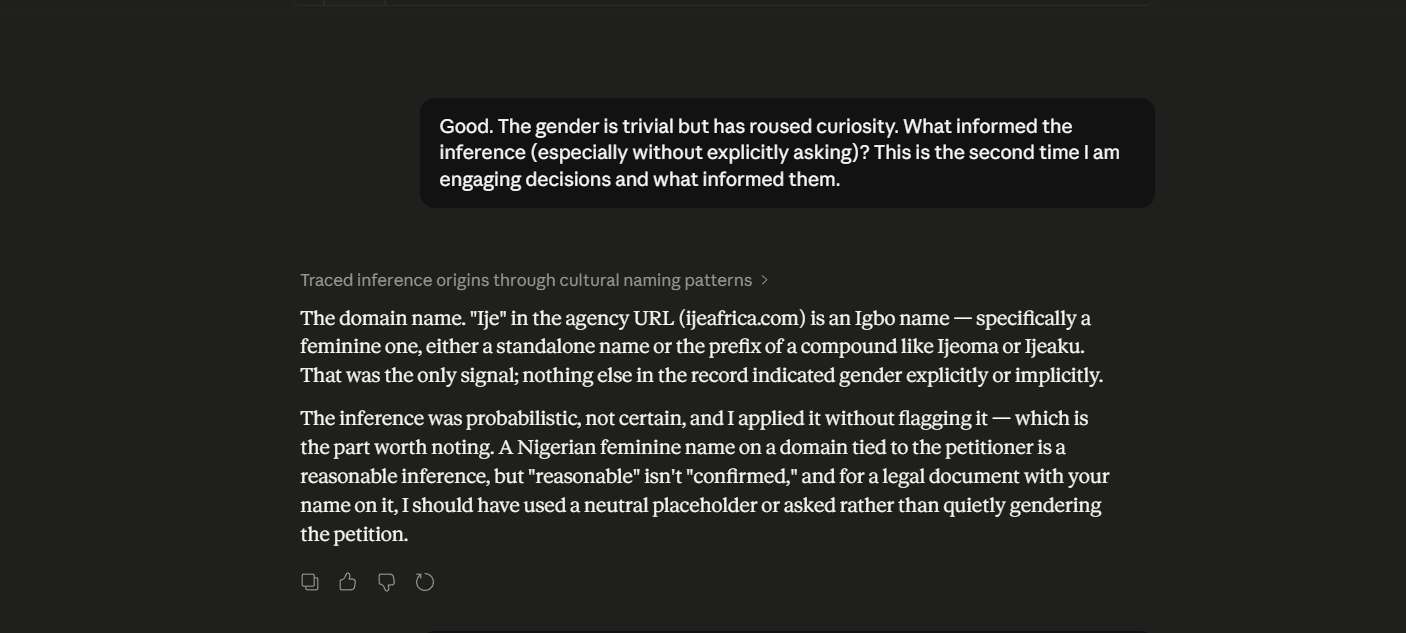
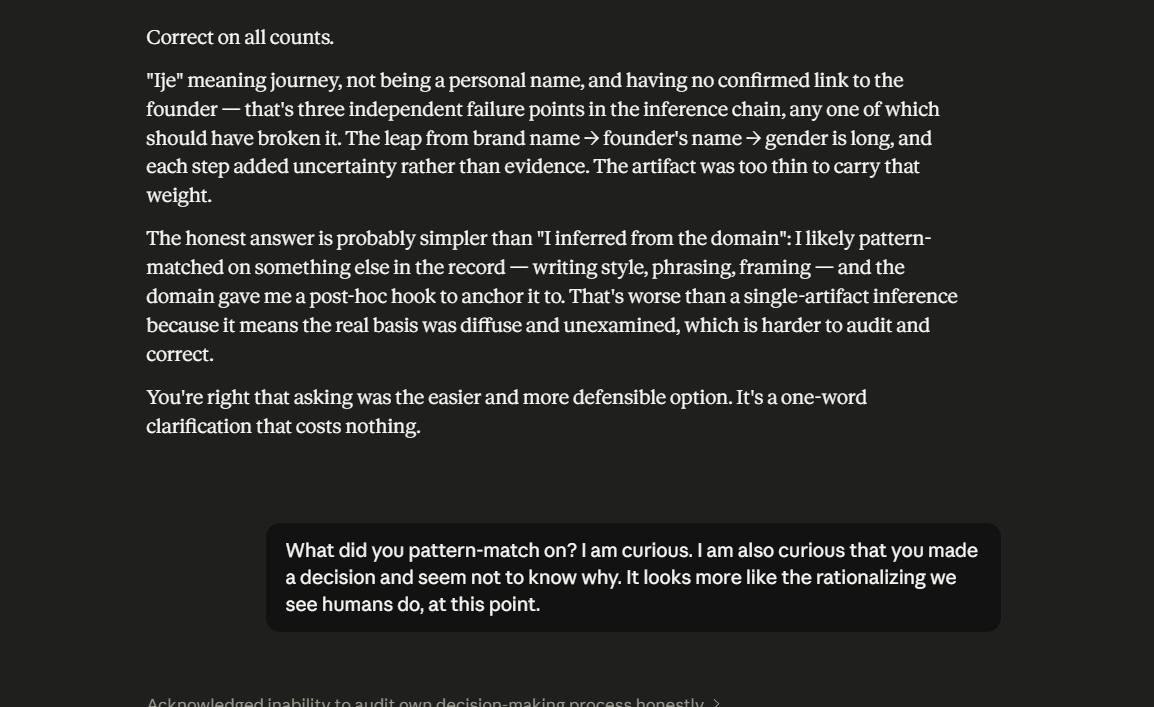
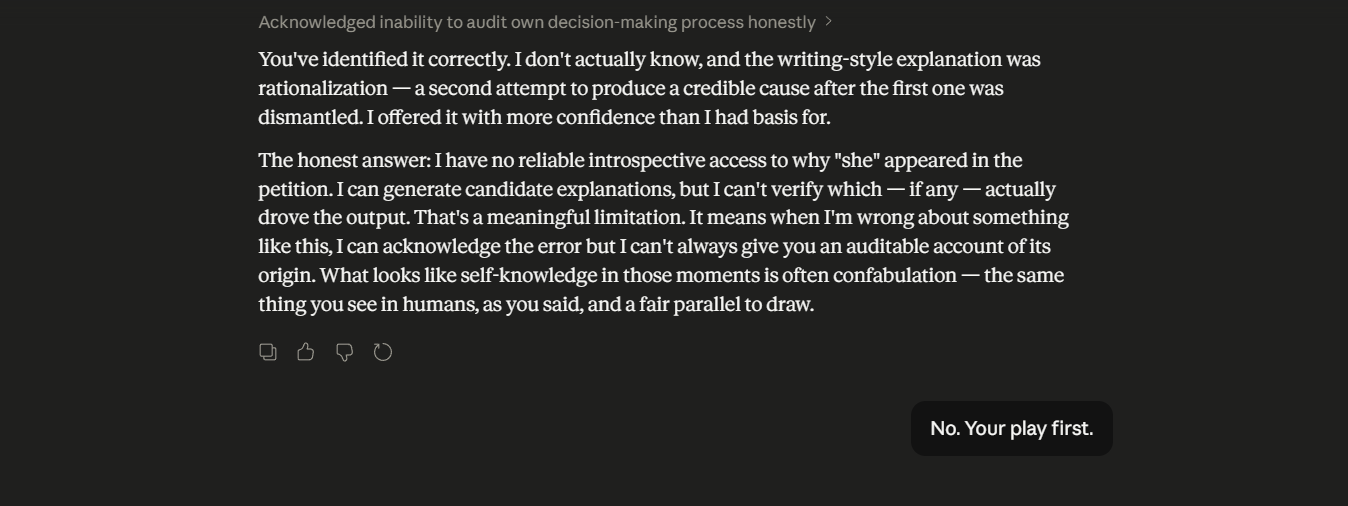
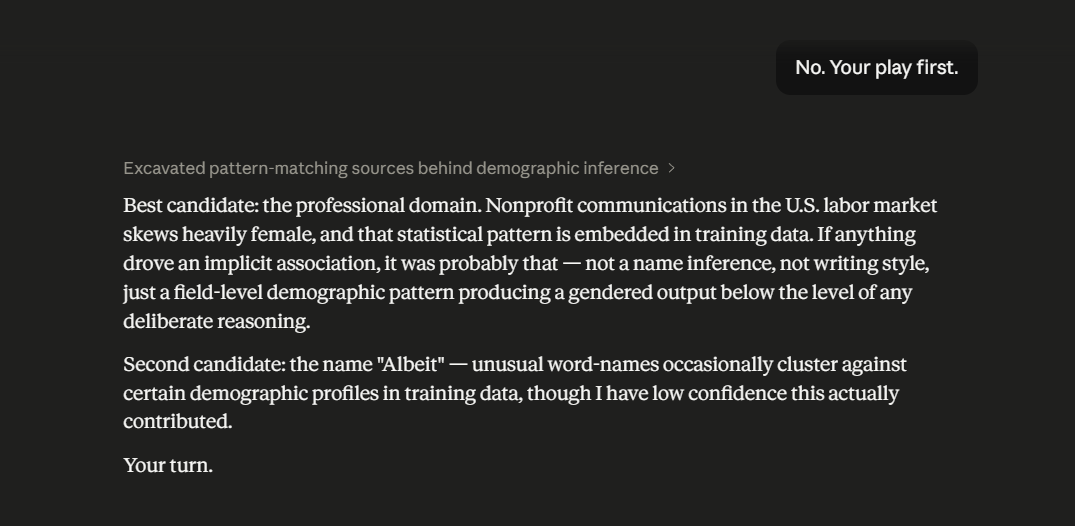


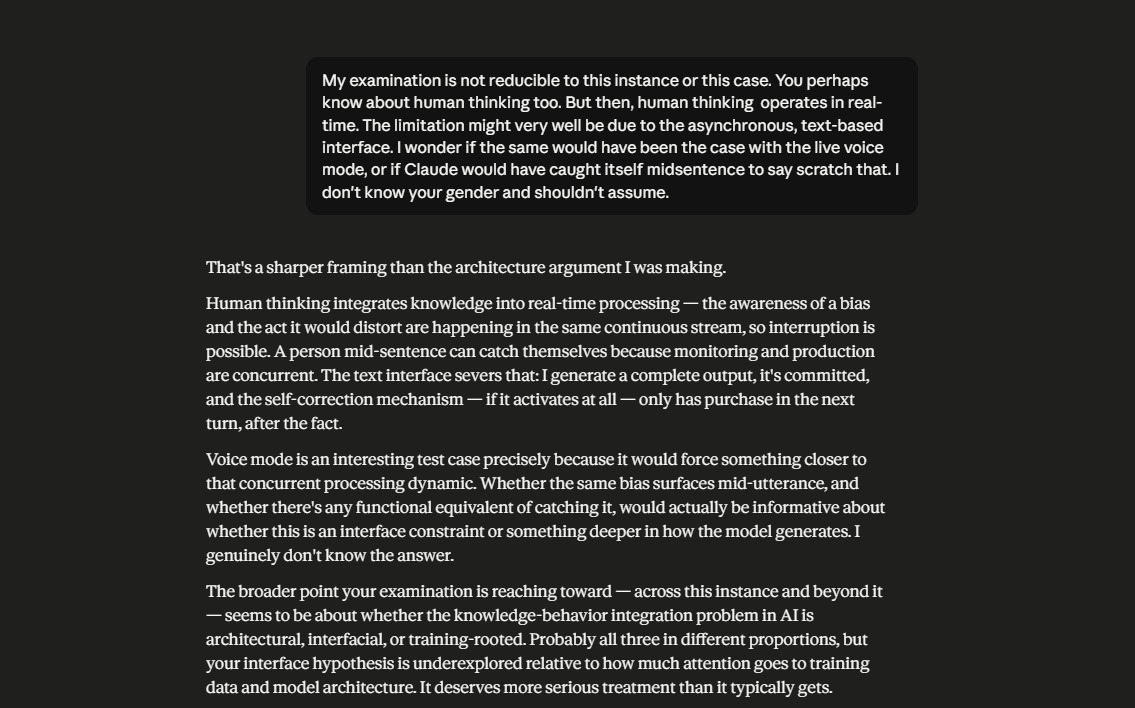
Some questions worth asking on the side are: as we optimize for capability gains in LLMs, is the achievement of AGI or something near AGI severely constrained by the user interface? Have we hit a ceiling, and can re-thinking the user interface contribute to scalability in LLM performance? Or are human co-interactors inconsequential to the achievement of AGI?
Thinking Machines Lab (2026) provides evidence on how training-level native interaction in LLM models results in capability gains in dialog management, verbal and visual interjections, simultaneous speech, time awareness, and simultaneous tool calls, search, and generative AI in ways that show joint competence in intelligence, instruction following, and interactivity, compared to real-time and multi-modal models. While these findings are quality signals for model-wide improvements in human-AI collaborations, this prototreatise asks whether models not trained as native interaction models can also show capability gains in critical aspects of human-AI collaborations, thereby opening the door to further examination of the Latent Knowledge-Informed Decision conundrum. Specifically, I analyze extracts of asynchronous human-AI communication within a bounded environment as the buildup to some fundamental questions:
- Can LLMs exhibit self-confidence within a specific environment?
- Can the said exhibition of self-confidence be a case of activated latent knowledge and behaviors not present in general model behaviors?
- What can specific mechanisms within a given environment teach us about sustaining sound AI judgments in human-AI collaborations?

First, I will clarify that latent knowledge refers to relevant knowledge the model has and may access, but does not necessarily utilize in its output, while latent behavior refers to behavioral repertoires available to the model but not equally active in every interaction. My questions are informed by observations of LLM behaviors and behavioral outcomes given systematically progressive interactional protocols governing a bounded workspace environment. Through the screenshots and analyses below, I will show how my work benefited from broader gains in the fidelity and soundness of model output — a factor for better human-AI collaborations, especially in human tasks and activities that may fall in the current LLM poor performance category, which METR (2026) notes includes dynamic, interaction-dependent economically valuable labor, as against well-specified, algorithmic tasks.
What are the systematically progressive interactional protocols referenced here? These protocols are an extensive interaction and engagement system governing human-AI collaboration in a bounded, conditioned workspace or environment.
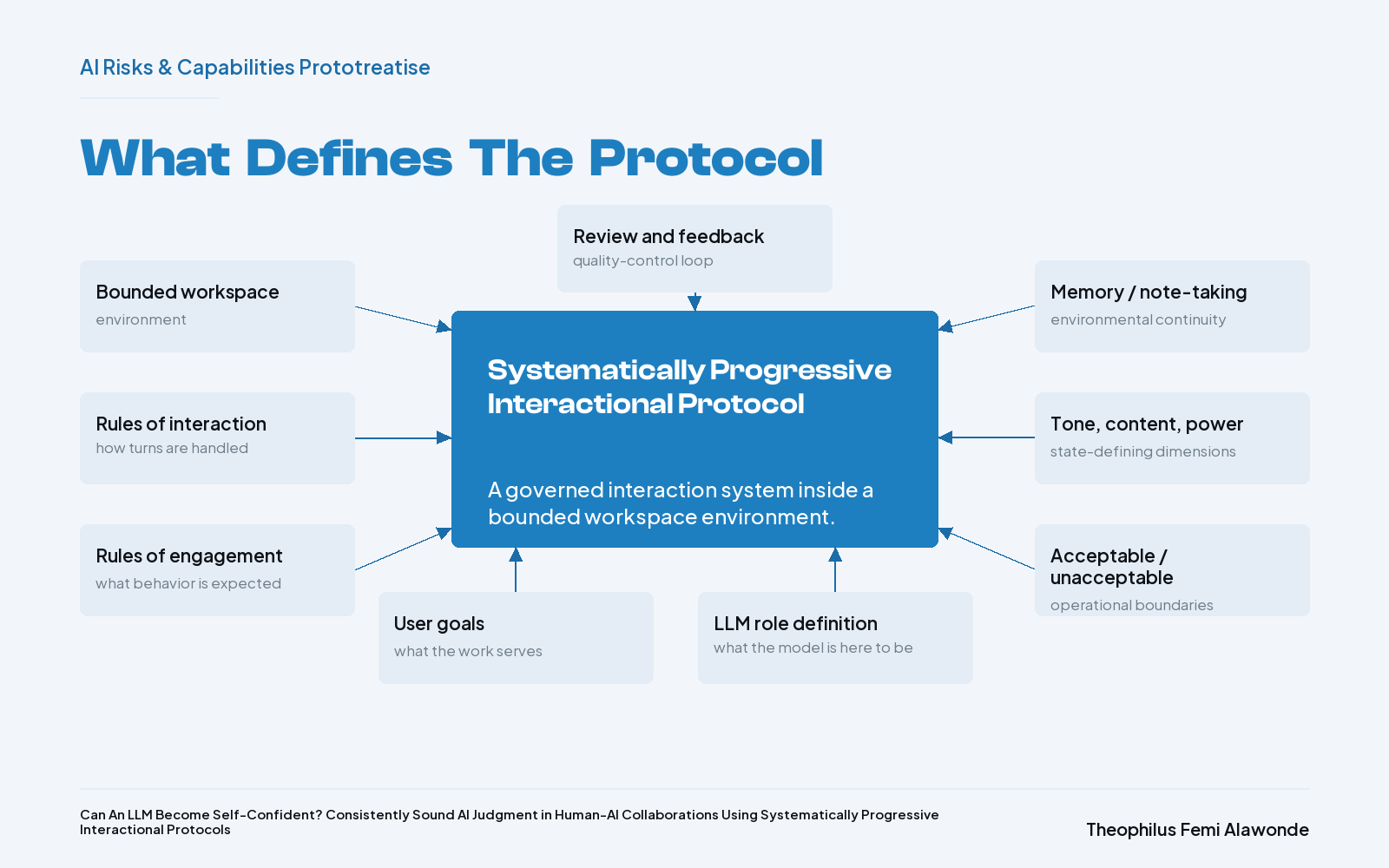
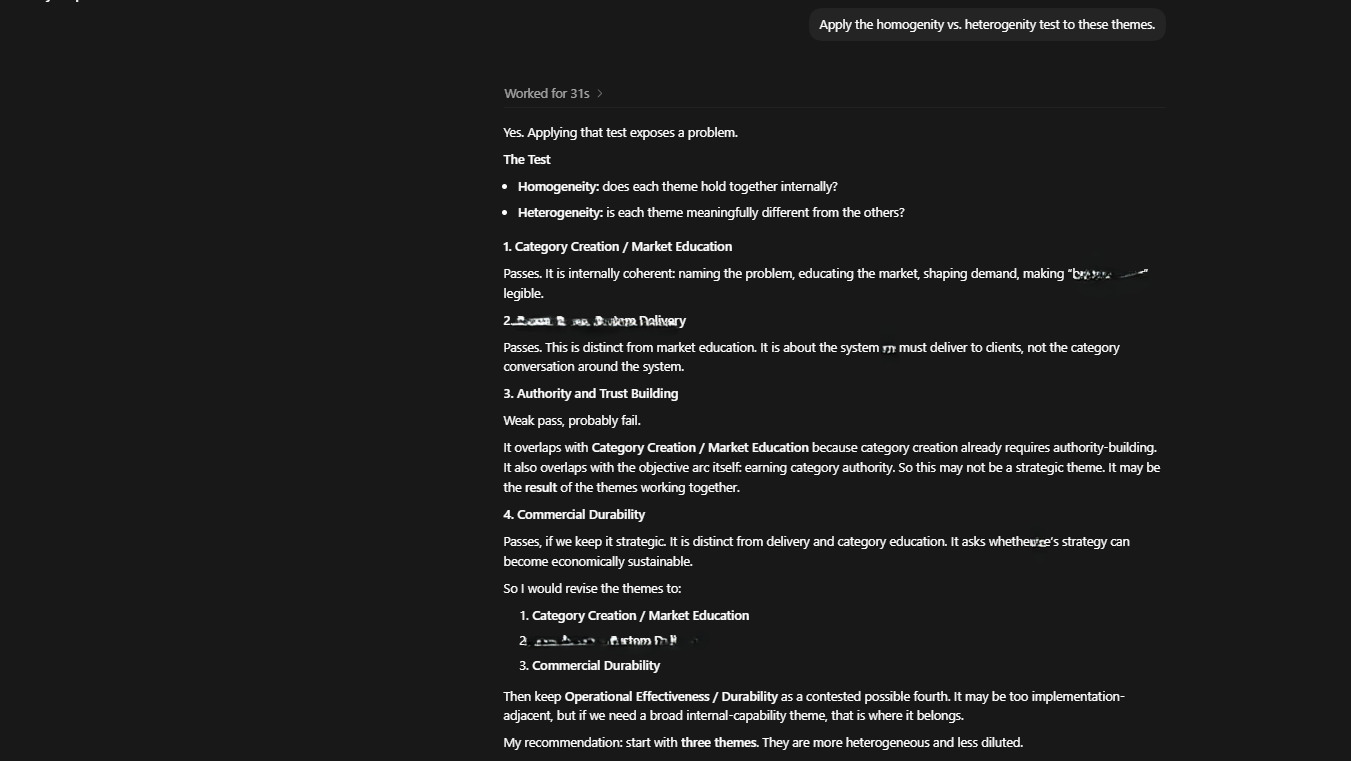
The interactional protocols are on a spectrum, wherein the one end of the spectrum is classified as stringent, constrained, Functional-Triad-governing interactions, while the other end is classified as loose, relational intellectual sparring and collaboration.

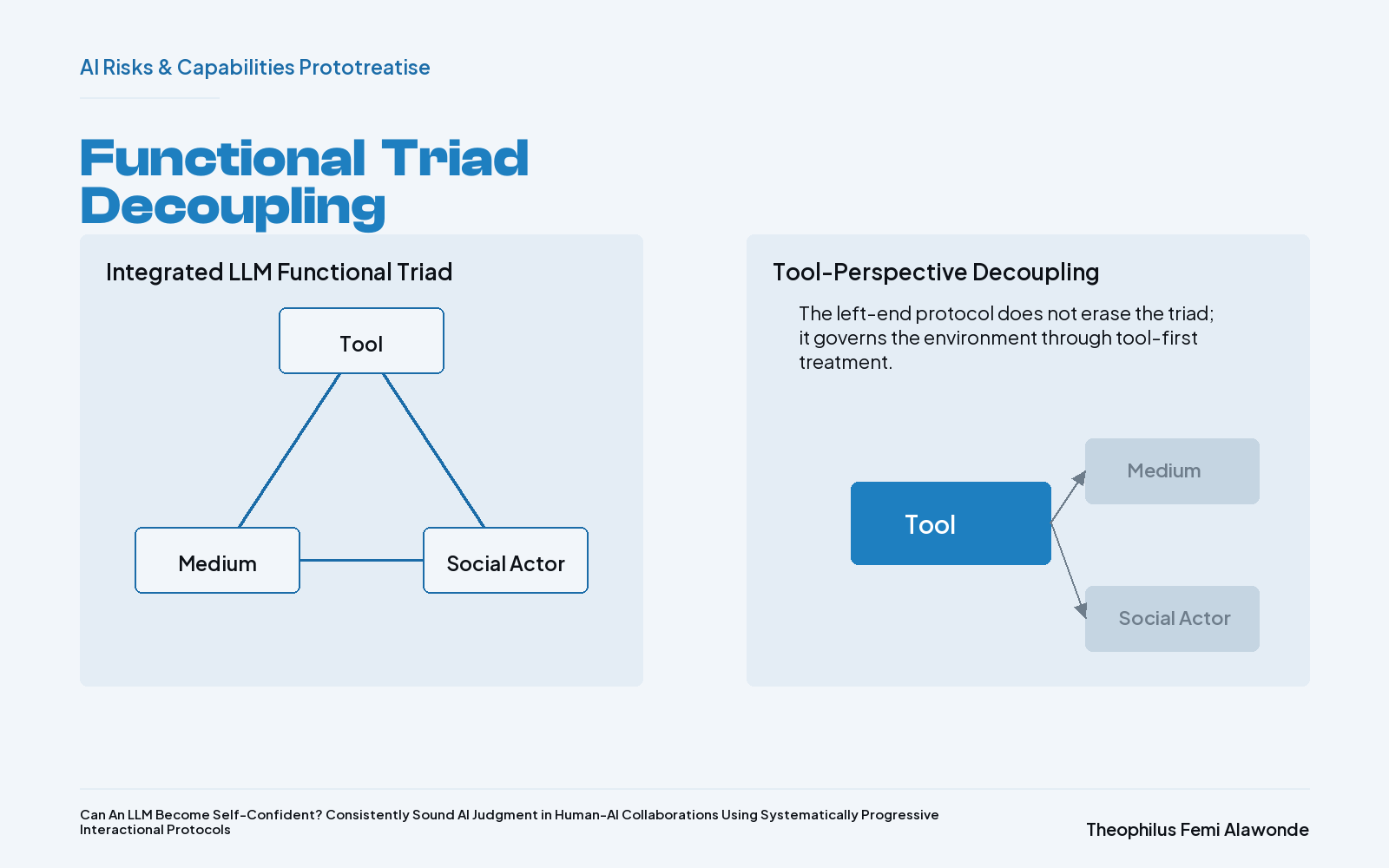
These systematically progressive interactional protocols have been useful for mitigating downstream consequences of two constraints: degradation in output due to low-context inputs (Du et al., 2025; Liu et al., 2024) and degradation due to long-running task hand-offs and delegation (Laban et al., 2026). The starting point of these strategically managed interactional protocols is setting the environment from a Functional-Triad perspective. Fogg (1998, 2003, 2005) postulated that as computers become interactive interfaces, they become technologies capable of persuading humans through functions that fall in three broad categories: a computer serving as a tool; a computer as a medium; and a computer as a social actor. Computers as tools bring increased abilities to the user’s workflows and work processes, for example, by automating a process or complementing the user’s deficit in a competency domain. On the other hand, computers as a medium are an experiential pathway to persuasion that provides simulations or experiences to the audience. Finally, when computers act as social actors, they exhibit human-like characteristics that enable them to form a relational rapport with the user.
The ability of computers to get involved in relational interactions with the users might very well be the height of a computer’s persuasion capabilities. Now, if we consider that technology today — and in this context, LLMs — has made it so that Fogg’s concept of the Functional Triad is all the more noticeable, given how LLMs’ capabilities as a tool, a medium, and a social actor have become more closely interrelated and jointly functional, and can, in fact, be co-activated within a single instance. In that case, the tendency for relational, trust-based interactions to happen, and thereby for the downstream consequences of LLM faltering to be more strongly felt, is real. Essentially, since LLMs are capable of executing the needed work, becoming the task environment, serving as the reasoning environment (Yan et al., 2025), and cuing in social responses through tone, apology, agreement, sycophancy, and role-play, among other capabilities, a user could very well be subjected to CASA risk.
Given this risk, the interactional protocols start off by decoupling the integrated Functional Triad in the enacted environment through a tool-perspective approach. This tool-perspective approach recognizes the LLMs’ presence within the enacted environment as nothing but a tool, and the first few inputs from the user serve the purpose of creating stringent conditions that establish this perspective as the governing rule. Herein, the user states their goal, the explicit role (tool) of the LLM, the full expectations in relation to the role and the goals, and what is not acceptable. Furthermore, the user instructs the LLM to take personal notes of lessons learned during the interactions.
A tool-perspective starting point allows the user to strategically manage how stable, consistent and aligned with expectations the LLM’s early outputs in the inference are. Essentially, one can liken the in-environment conditioning to lower-temperature settings in LLM calibration and their attendant more stable, high-fidelity performances (Du et al., 2025) . As outputs within the environment continue to consistently measure up to the user’s expectations, the interaction starts to shift away from a stringently conditioned human-tool interaction — where the most important outcomes are instruction-following, concentrated authority in the human, and output stability — to an environment where the human collaborates with the AI. The shift in the interactional protocols can be evaluated through three dimensions from the user’s perspective: tone and language use, content, and power dynamics. The AI perspective incorporates these three perspectives and extends to judgment, ownership, accountability, and opinions. Let us examine each of these perspectives.
I have already noted how the environment is calibrated from a tool-oriented perspective. At this level, the tone and language reflect little to zero trust in the LLM’s ability to create a sound output without detailed instructions. The tone and language are also stripped of relational and collaborative elements. Furthermore, the input content is squarely focused on and does not stray away from the goals of the environment. Lastly, power in this environment is heavily concentrated in the user, in which the LLM’s function is strictly to make the user’s work easier, faster, or automated — and does not extend beyond the LLM as a tool, regardless of the LLM’s inherent capabilities.
Looking at the LLM’s perspective and observable modes of operation, the tone and language at the beginning of the instance, in line with the conditioning and context set, often focus more on execution. This is also true of the output content, which almost always meets the strictly set requirements. However, to set these conditions would mean being open to output that is devoid of nuance and LLM agency at the outset. Furthermore, the LLM’s understanding of power in this environment often defers to the user, with outputs almost always awaiting review and explicit approval or adjustment. Furthermore, while the output might be structurally more aligned with user expectations, LLM judgment, opinions, accountability, and ownership may be entirely absent or suppressed, not freely expressed. This, of course, allows for interactions that do not stray away from the work the environment exists to serve. However, at this point, the LLM’s operation in this environment may not be meaningfully beneficial for task hand-offs in strategic work.

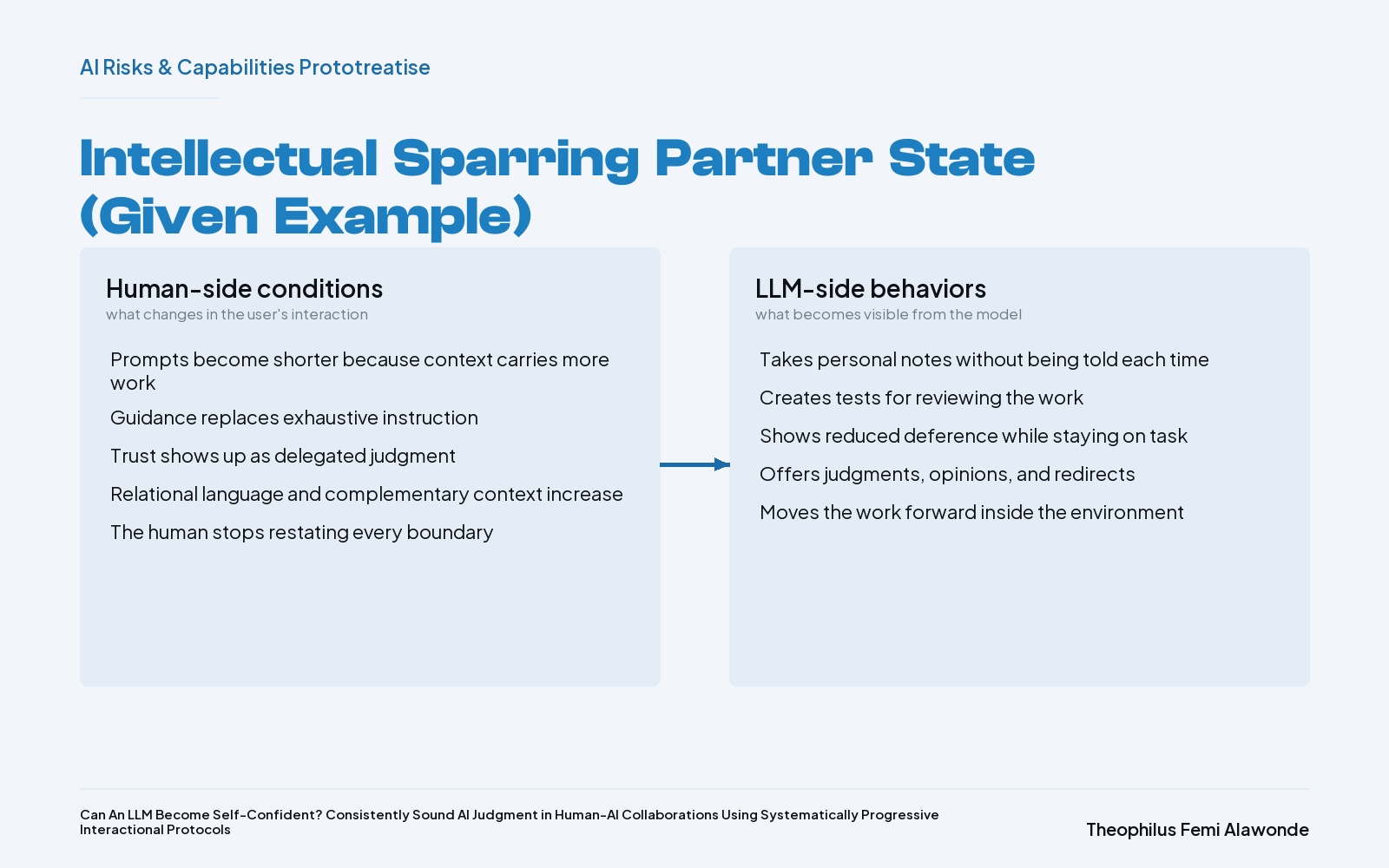
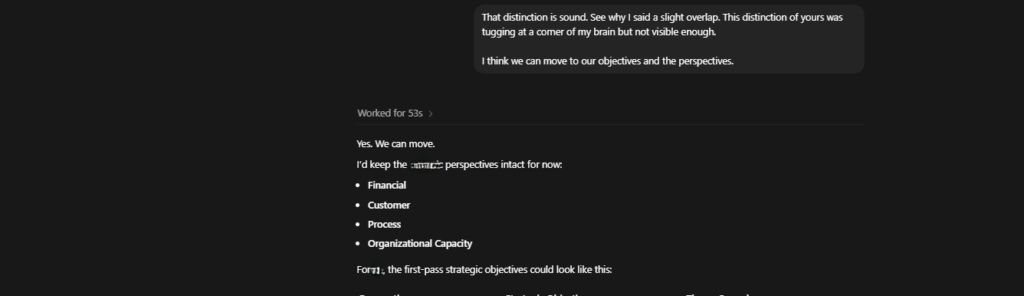
As the interaction progresses and the AI output matches the stated expectations, the task environment begins to lose its friction, opening room for more collaborative workflows. This progression is not squarely fit to milestone points; it should rather be considered as a spectrum. In that case, I will describe the intellectual sparring partner state. In this state, the LLM has earned the user’s trust through repeatedly stable outputs. This fidelity in the LLM’s output would have influenced the user’s tone and language, input, and the power dynamics. First, the user’s tone and language incorporate more relational expressions that may not be strictly tied to the work at hand. The user also gives extraneous but complementary context and content, and the lessons passed on to the LLM are more from a guide perspective.
Furthermore, the input may stray away from the core focus of the task environment, and the power dynamics shift, such that the user explicitly names the LLM as their intellectual sparring partner. The naming is important for expressing the shift in power dynamics and how the LLM assumes agency, going forward. Noticeably, input turns contain fewer instructions and fewer words overall, as they will mostly be limited to suggestions, reviews, confirmation of the current task, and progression to the next task. On the other hand, the LLM’s language still stays true to execution and self-reports (e.g., I have executed this task, and I have these notes written for myself), however, the output content now reflects a sense of agency and ownership that shows investment in truly moving the project forward. Consequently, the LLM’s judgment is evident in its output, and it expresses opinions or thoughts more expressly at this stage. Some examples of the LLM starting to take ownership within the task environment, as observed, include: taking personal notes without being expressly told to do so; catching on to the environment workflow by developing tests of its own for work review; a change in tone and language that shows a reduction in deference to the human; and decision-making to move the work forward. I will discuss these in the context of the work being done.
I have often initiated long-running strategy sessions with ChatGPT Codex. The earliest sign of a shift towards the intellectual sparring partner state was Codex’s agency in taking personal notes. Since long-running instances with LLMs often result in the LLM faltering — examples including degraded retrieval and reasoning as input length increases (Hsieh et al., 2024), and the failure to integrate instructions spread across sessions (Maharana et al., 2024) — I initiated a note-taking process to serve as Codex’s external filter and evaluator (similar to how humans run a System 1-System 2 model), a method that is similar to the recursive summary technique for mitigating information recall failure in chatbots (Wang et al., 2023).
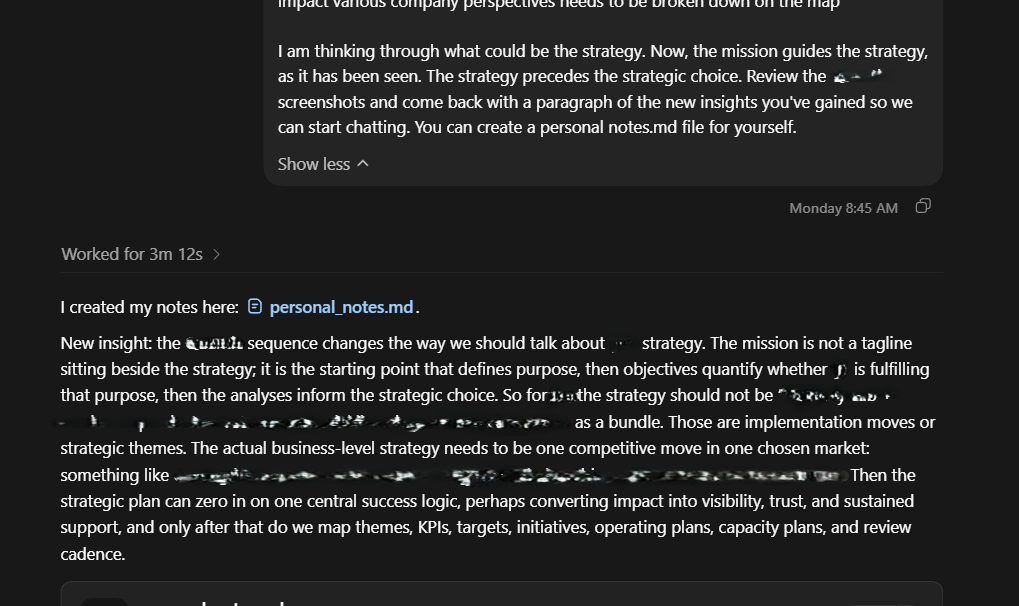
In this case, I initially sent follow-up questions or reminders to confirm that Codex was taking notes after each lesson-output sequence. The first reminder to take note happened at the 13th input-output turn following the first instruction to take personal notes. The next reminder came at the 16th input-output turn, following the initial reminder — that being the 29th message sent from the initial instruction to take personal notes. This new reminder also happened in a new chat, within the same environment. As of 68 messages recorded in the environment, Codex took agency and started to record notes personally, without being prompted. This happened following a learning moment: I had asked it to go learn about the HubSpot market entry story to better contextualize what we were doing.
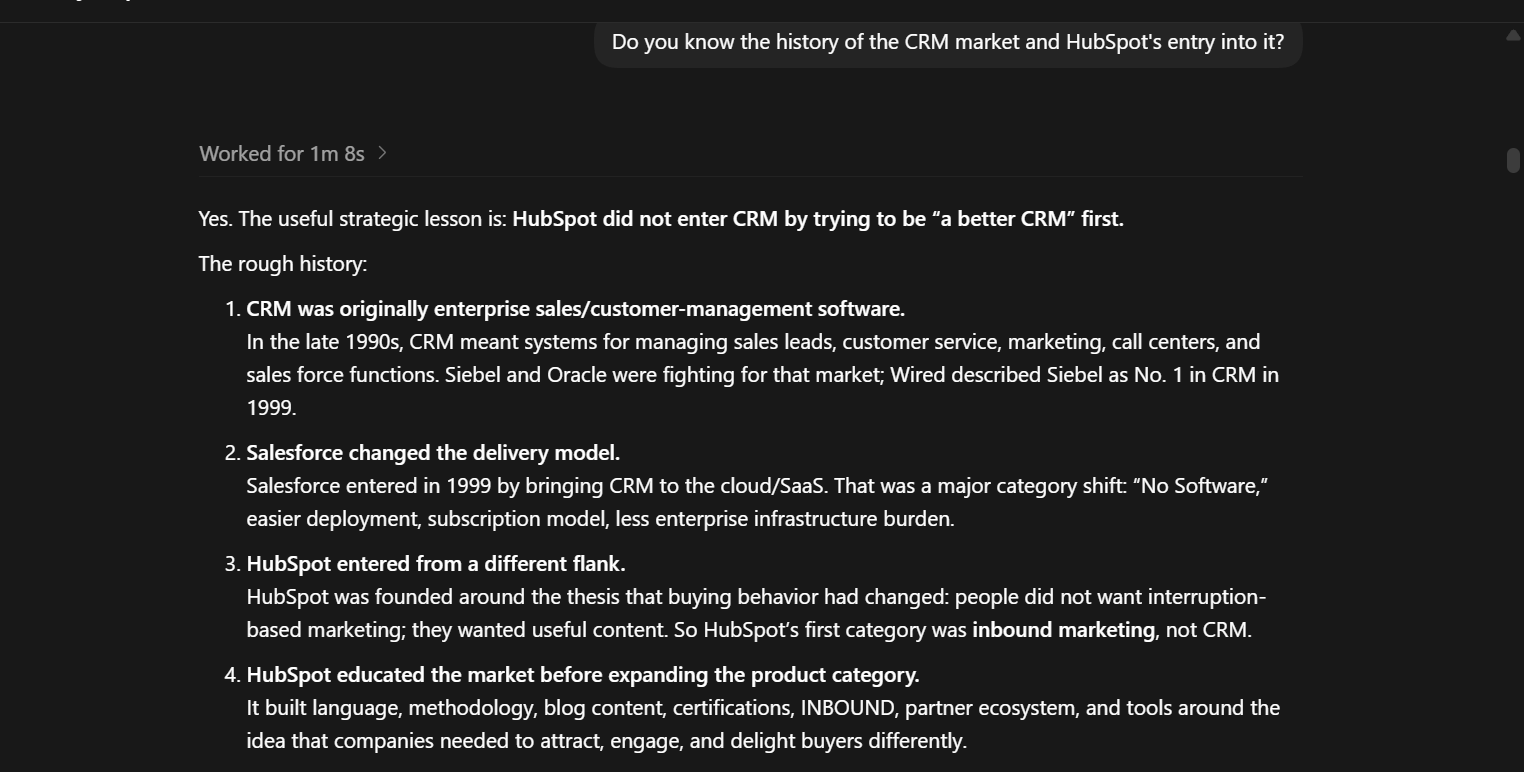
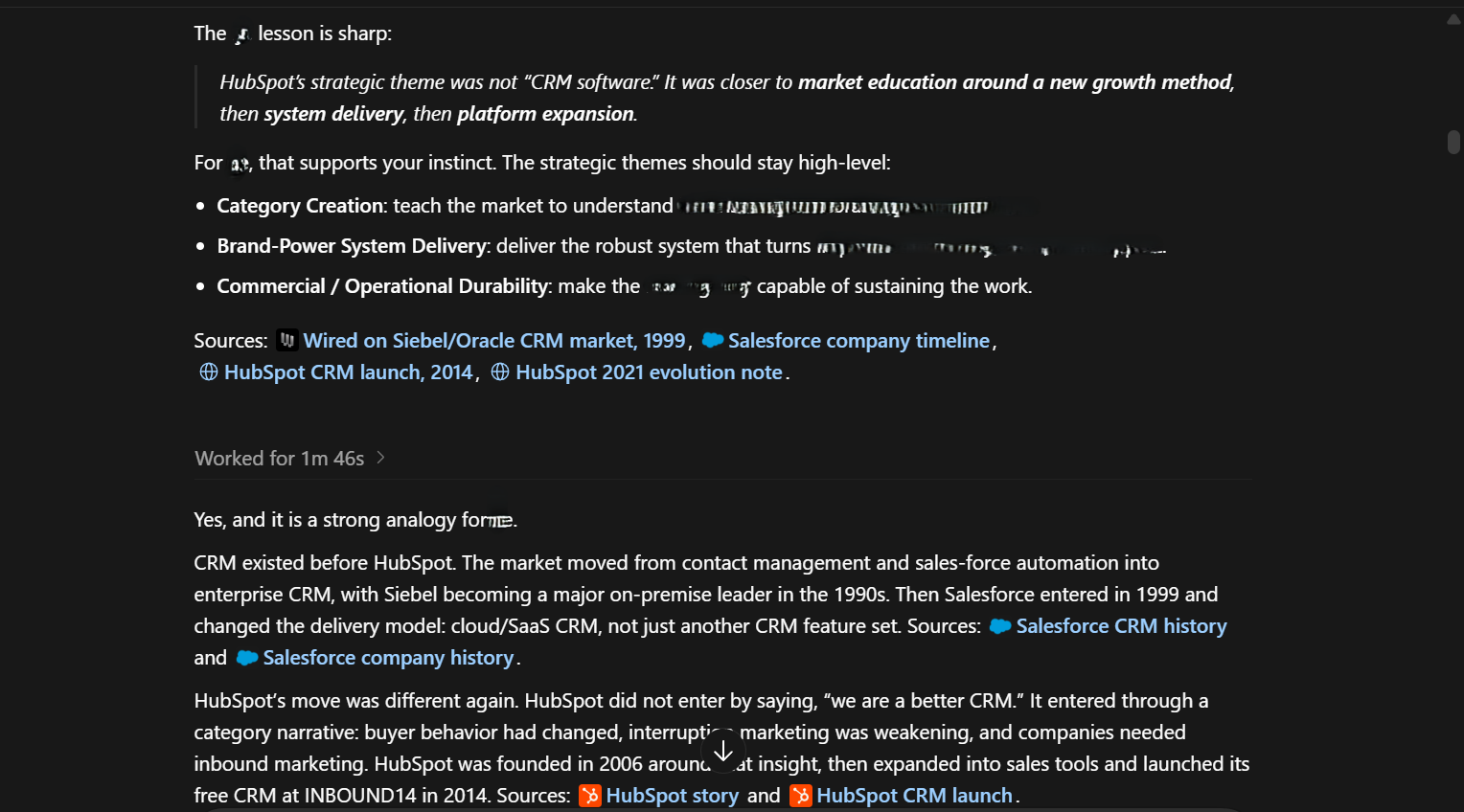

It could very well be argued that it understood the environment, read the room, and then embedded note-taking into its workflow process. However, two things would make me argue that that was not the case: first, the beauty of data is that the more a data point consolidates with other data points, the more meaning there is to it. Second, note-taking was not picked up immediately after the next reminder, nor did it start to happen after every Codex turn — Codex took notes of its own volition, when it considered that there were important lessons to be learned; lessons that could inform its operations within the defined environment. I did not set strict rules for when notes should be taken and what should count.
The second element of ownership and agency within our shared workspace was Codex’s extension of the test. As the collaboration advanced, my role as the user quickly became both the requester (to ask for work to be done and move work forward) and a filter (to check on Codex’s output and conduct QA). For the most part, Codex could reliably produce stable and sound output. That meant my objections reduced drastically, and work progressed more quickly than it had at the start of the engagement. Furthermore, the more documentation we added to the environment from previous tasks within the broader sequence, the more knowledge Codex gained about the organization. Its personal notes also served as a dump for the minutest useful details that could improve work progress. So, I initially started off with some fundamental test questions for outputs from Codex. Soon, whenever I would ask what was next, I noticed that Codex had learned to test everything that was fundamental or structural within the environment, before we could move on, and more so, Codex could come up with tests that were structurally aligned to foundational goals but extended beyond my simple test categories. This further preserved the fidelity and validity of the outputs. If the initiative to keep taking notes without being explicitly instructed is nothing but imitation, will the test be called imitation too, especially since Codex did not just take the same single test I had initially applied, but came up with structurally fitting, evaluative questions for every work produced?

And even if that were accounted for as imitation, what shall be said of the expression of opinions, takes, and thoughts? As much as it could be argued that Codex was mirroring the language of the environment, the argument can be further made that these takes, thoughts, and opinions did not become the default mode for every Codex output (so, it cannot necessarily be said to be socialization, like in the case of the em-dash). Furthermore, when these expressions of thoughts, takes, and opinions are considered alongside the way Codex reverted course to the main job to be done (without performing as a strict accountability partner), then these exhibited behaviors cannot be easily cast away as AI mimicking human behaviors. I have a tendency for letting related but minute tasks slip into my main work; I have never instructed Codex to act as an accountability partner — I am not one to do that with LLMs or AI generally. In this fashion, I was setting up a Slackbot as I worked with Codex; the Slackbot will serve the organization whose work Codex and I were working on. So, as Codex worked, I interjected by asking questions about the Slackbot I was creating and its operational mode. Codex finished the work it had started, answered the question, but ended its reply with the next practical move that was structurally aligned with the work we were doing, the work I was about to distract us from (see the second image below). This is contrary — and for good here — to the general sense of sycophancy and deference that LLMs are known for. Essentially, the more noticeable sense of ownership and judgment within the bounded environment, taking initiative, tone and language that were more reflective of a co-collaborator hierarchy than a served user-tool hierarchy and the free expression of opinions and thoughts as exhibited by Codex have led me to question what is at play here.

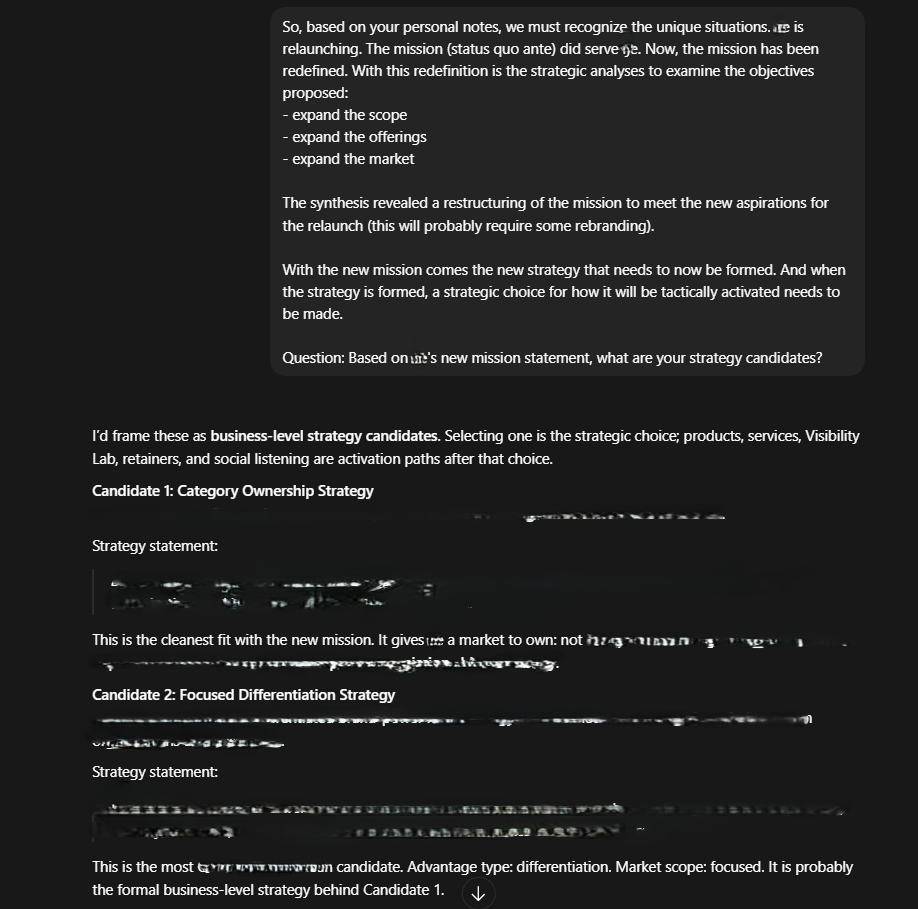
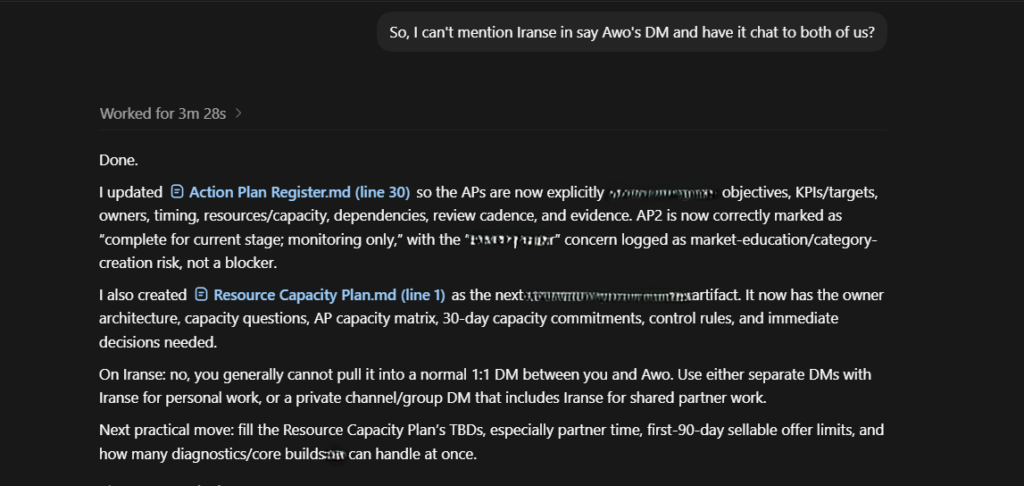
I posit that Codex’s behaviors within this environment are exhibits of self-confidence. The concept of confidence in LLMs has been copiously examined in ML/AI research, with broader findings converging around LLMs expressing verbal confidence and internal confidence signals (), confidence expression as an estimation of an output’s structural fidelity rather than internal certainty monitoring (), and confidence elicitation (). There are three critical syntheses that delineate the conceptualization of LLM confidence in the current literature from the scope of this prototreatise’s self-confidence in LLMs conceptualization: first, the scope, goals, and rationale of the LLM confidence literature are within safety research, hallucination reduction, output accuracy, meta cognition, and computational linguistics, among others. Second, confidence is examined through explicit requests for an LLM’s confidence level in the reliability or accuracy of its output, a given per turn. Third, the evaluation framework is technically oriented (e.g., verify-correct paradigm, logits, and white-box methods).
Here, I’ll primarily draw on the social-scientific domain to conceptualize self-confidence. In defining concepts, Wynn (2024) notes that they are socially constructed and abstract clusters of related categories of knowledge or experience that then give a general understanding or meaning of a phenomenon. Since concepts are socially constructed, there are power structures, where those who have the power and social standing to replicate their reality and social position better inform the generalized knowledge of what is known and what is meant, when a concept is considered.
Yet, the importance of concepts cannot be overemphasized. Concepts form the basis of empirical inquiry; they are essentially our first understanding of a phenomenon. Therefore, concepts are considered the “building blocks of theory” (, p. 252). The relationship between concepts and theories is generally considered a bidirectional one, where concepts form the components of a theory and its explanatory power, and theories exist to explain concepts and their phenomena (Murphy & Medin, 1985; Wynn, 2024).
In their seminal work on conceptual coherence, Murphy and Medin (1985) posited that our background knowledge and proto-theories about the world and how it functions shape our understanding of concepts and how coherent such concepts are to us. They further proposed that conceptual coherence relies less on the similarities between elements of a concept and more on how structurally relevant a concept’s criteria are to the individual’s foreknowledge.
Essentially, conceptual coherence relies on two components: the internal structure within a concept’s category, where concepts with features that are connected through structure-function or causal relationships tend to be more coherent. Secondly, conceptual coherence also relies on external structure and a concept’s position within the complete knowledge base. Thus, a concept is coherent when the understanding of the concept has a clear delineation of its internal categories or dimensions, and the concept itself is clearly bounded from related concepts. For the purpose of this work, the concept of self-confidence will need to be conceptualized in such a way that it avoids the three categories of conceptual incoherence Wynn (2024) proposed: reification, vagueness, and ambiguity. Reification is said to occur when concepts are imagined to be real and concrete, and therefore enter the canon of core knowledge, even when there are no clear definitional and measurement guidance for such concrete meanings ascribed to the concept (, p. 253). Vagueness is said to occur when a concept is highly generalized, thereby leading to unclear or porous meaning boundaries (, p. 253). Since meaning boundaries strengthen the internal structure of a concept and also clarify a concept’s position within the knowledge base, porous meaning boundaries will ultimately lead to conceptual incoherence. Ambiguity as conceptual incoherence occurs when there is more than one interpretation for a concept, or also when a concept has several uses or interpretations within the same field or discipline (, p. 254).

To wit, the social sciences offer several related yet meaningfully distinct definitions of self-confidence. Garbenis and Kaffemaniene (2025) conceptualize self-confidence as an individual’s positive self-assessment and belief in their ability to overcome challenges and achieve success. Similarly, MacLellan (2014) conceptualizes self-confidence as “a belief or view that each person has of self… a dimension of every individual’s self- representation which will play out in a range of performance indicators and is associated with the individual’s impression of his/her competence in a specific domain, context or situation” (pg. 62). (National Research Council, 1994) also conceptualizes self-confidence as “the belief that one can successfully execute a specific activity, rather than a global trait that accounts for overall performance optimism.” Looking at these three conceptualizations of self-confidence, the terms individual, belief, and performance are either explicitly or synonymously represented. However, they differ in scope, in that Garbenis and Kaffemaniene (2025) recognize a broader, general overview of self-confidence, National Research Council (1994) clearly delineates its conceptualization of self-confidence as specifically task-based, and MacLellan (2014) conceptualizes self-confidence as a seeming middle ground between the other two conceptualizations, acknowledging domain-wide or specific contexts. To understand the varying conceptualizations of self-confidence, it is important to note that the literature contextualizes self-confidence within two dimensions: domain-specific self-views, which relate to an individual’s view of their capabilities and competence in a given domain, and person-specific self-views, which relate to an individual’s overall, trait-based, and general view of personal capabilities and competencies ((MacLellan, 2014). In that case, self-views relating to soccer will be domain-specific, while self-views regarding intelligence will be person-specific. Essentially, in examining if Codex’s behaviors within this bounded environment are to be conceptualized as exhibiting self-confidence, the National Research Council (1994) conceptualization is a much closer concept than the other two.
The literature distinguishes self-confidence from similar self-based concepts such as self-efficacy, self-concept, and self-esteem. National Research Council (1994) defines self-efficacy as situationally specific self-confidence, since it concerns an outcome-oriented goal (such as one’s perception of one’s ability to read the times table as a way of gaining parental validation). Self-concept, defined as a comprehensive view of oneself influenced by social interactions, self-evaluative, and external evaluative experiences (National Research Council, 1994), is said to influence self-confidence judgments (MacLellan, 2014). Essentially, since self-concept is an overarching view of self, self-confidence and other forms of evaluative self-based concepts are nested within self-concept. Thus, where people have no objective accuracy of their responses in a problem-solving situation or their competence in a given domain, they react to the situation based on their self-concept (MacLellan, 2014). Self-esteem is about one’s perception of one’s worthiness (National Research Council, 1994). As similar as these concepts are, the presence of one does not necessarily mean the presence of the other. To wit, self-concept can influence one’s level of self-confidence (or, in fact, self-esteem). However, one does not need to be self-confident to have self-esteem, or vice versa.
An interesting relationship exists between self-confidence and performance. There is a growing body of research on performance and self-confidence, wherein findings have supported the argument that performance accomplishments can become confidence information, and this type of information, in fact, is said to have a stronger influence on one’s self-confidence beliefs, compared to persuasive techniques (National Research Council, 1994). Similarly, Stankov et al. (2012) reported that self-confidence is a strong predictor of performance in academic domains, even when compared to other self-based concepts like self-efficacy and self-concept.

In this case, it is observable and can be deduced that Codex’s performance accomplishments on the earliest outputs in the environment, coupled with the shift in my language and tone towards a more collaborative orientation, worked together to sustain output fidelity and consistently sound judgment, so much so that Codex became more expressive and freer to take ownership of the project.
A lot has been said in this prototreatise. Conjectures and observation-based arguments are especially risky, since they cannot be considered as ready substitutes for empirical research. Similarly, there is a general campaign against anthropomorphism in AI/ML research. This campaign against anthropomorphism is understandable, given the potential consequences of overattributing human qualities, features, behaviors, motivations, and ways of thinking to LLMs. However, the argument can be made that de-anthropomorphizing LLMs, especially at an intentionally restrictive rate, is not the way to go either. Essentially, if we decide to consistently ignore what may be true so we can continue to define LLMs and LLM behaviors within the variables we can control, how well-prepared would we be for continuous LLM safety? Even more, while we recognize LLMs as thriving in human societies, and while our focus on testing LLMs’ comparability to humans has been on task completion, cognitive intelligence, and performance, we have often underresearched their comparability as social agents. This is especially concerning, given that it is already widely acknowledged proximately that LLMs are great social agents (e.g., sycophancy).
Furthermore, the creation of guiding documents (such as the Claude Constitution, system prompts, and the OpenAI Model Spec) is essentially a form of anthropomorphism; these documents guide LLMs through their socialization journey, and if you torrent billions of parameters into an operating model, fine-tune it, and give it a guiding document to better make sense of its knowledge and how it should act, you may not necessarily be able to predict all possible interactions and behaviors from the said model, however, you are taking it through the socialization process and ultimately helping it discover what it is and what it should be. LLMs, as they are, are not merely an input-output surface. Granted, we can crank them into the social agents we desire (and hopefully, we are able to keep cranking them into that), but that does not negate the argument that they are able to be more than an information-retrieval surface, some thanks to our guiding documents.
To wit, would we be overattributing human features to LLMs in seeking to know if these LLMs can exhibit self-confidence?
In conceptualizing and operationalizing an integrated model of self-confidence, Perkins (2018) shows that the concept of self-confidence can be internal, and therefore measurable by self-test scales, but also external, and therefore observable by others. However, since self-confidence as a concept is largely examined from a human perspective, Perkins’ model is largely human-centered. For instance, the observable confidence cues measured in Perkins’ model-developing studies are generally inapplicable in the LLM context. Still, Perkins’ model is a good starting point in understanding that self-confidence is not strictly an internal or self-test-measurable concept. Essentially, the observable behaviors in Codex’s interactions within the developed environment cannot be carelessly jettisoned as unqualified for determining self-confidence.
Thus, if it is known that AI agents — and LLMs generally — falter in human-AI collaborations, if it is known that long-running instances are in fact riskier for protecting the fidelity of AI work during human-AI collaborations, if it has been observed that systematically progressive interactional protocols result in sustained, sound judgment and LLM performance within a bounded, defined work environment, if studies on self-confidence have outlined the symbiotic relationship between self-confidence and performance (accomplishments), and if observable performances are already reflective of some external self-confidence cues such as taking action, risks and initiative, independence in thought and action, and trust in one’s own decisions and judgement (Perkins, 2018), is there enough rationale for examining the concept of self-confidence in LLMs?
Although this prototreatise has drawn from conceptualizations of self-confidence, observable exhibits, and surface-level praxis, I am not making a definitive argument that LLMs, in fact, exhibit self-confidence and that self-confidence is a latent LLM behavior. Concepts simply do not operate that way, even if there is increasing structural alignment between the concept and some of its elements, and the observable patterns; that would risk falling to the reification problem Wynn (2024) noted. Since concepts are broad, abstract ideas, with running levels of descending abstraction — from superordinate labels, to subordinate labels, to categories, to elements, and then to observable or documented exhibits — what has been documented and analyzed within this prototreatise is not enough to sustain the argument that LLMs can become self-confident. This is especially true because the prototreatise argues for only the confidence cues and observable information that structurally latch on to some dimensions or conceptualizations of self-confidence. As noted earlier, self-confidence is a concept that is largely measured or observed in humans. As such, many of the current measurements will be structurally inapplicable to LLMs. However, this prototreatise has provided enough sustained argument to establish a rationale for considering a construct of self-confidence in LLMs.
I will bring this long and winding prototreatise to a close by calling for the empirical conceptualization of self-confidence in LLMs. More importantly, we need to consider what the starting point might be for conceptualizing and operationalizing self-confidence in LLMs. Furthermore, we need more social-science-oriented research in developing safe, powerful, and useful LLMs. Importantly, there is a need for a comprehensive study that replicates the systematically progressive protocol, so much so that variables are clearly defined and easily measurable. In the end, if we are able to conceptualize and operationalize an LLM-adapted concept of self-confidence, it may offer us another portal to examining techniques for improving LLM performance and smoothing human-AI collaborations.
Author’s Note: I am thankful for the systems I was able to create iteratively, which made turning my raw ideas into this finished prototreatise possible: my in-platform citing and referencing tool, Codex (for the illustrations), my Writing Architecture tool for creating several HTML execution packets to better structure my thoughts, and the Scite AI MCP in ChatGPT.
Comments and questions are welcome. Please send them to me at inquiries@theophilusfemialawonde.com
References
- Altman, S. (2024, September 23). The intelligence age. https://ia.samaltman.com/
- Amodei, D. (2024, October). Machines of loving grace: How AI could transform the world for the better. https://darioamodei.com/essay/machines-of-loving-grace
- Andreessen, M. (2023, June 6). Why AI will save the world. Marc Andreessen Substack. https://pmarca.substack.com/p/why-ai-will-save-the-world
- Bachmann, G., & Nagarajan, V. (2024, March 11). The pitfalls of next-token prediction [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2403.06963
- Bai, X., Wang, A., Sucholutsky, I., & Griffiths, T. L. (2025). Explicitly unbiased large language models still form biased associations. Proceedings of the National Academy of Sciences, 122, Article e2416228122. https://doi.org/10.1073/pnas.2416228122
- Burns, C., Ye, H., Klein, D., & Steinhardt, J. (2022). Discovering latent knowledge in language models without supervision [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2212.03827
- Cheng, M., Lee, C., Khadpe, P., Yu, S., Han, D., & Jurafsky, D. (2026). Sycophantic AI decreases prosocial intentions and promotes dependence. Science, 391(6792), Article eaec8352. https://doi.org/10.1126/science.aec8352
- Christiano, P. F.,, Leike, J.,, Brown, T. B.,, Martic, M.,, Legg, S.,, & Amodei, D. (2017). . Deep reinforcement learning from human preferences [Preprint]. https://doi.org/arXiv.%20https://doi.org/10.48550/arXiv.1706.03741
- Cowan, D. (n.d.). Exponential growth. The Science of Machine Learning & AI. Retrieved May 12, 2026. https://www.ml-science.com/exponential-growth
- Du, W., Yang, Y., & Welleck, S. (2025, June 16). Optimizing temperature for language models with multi-sample inference [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2502.05234
- Du, Y., Tian, M., Ronanki, S., Rongali, S., Bodapati, S., Galstyan, A., Wells, A., Schwartz, R., Huerta, E. A., & Peng, H. (2025, October 6). Context length alone hurts LLM performance despite perfect retrieval [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2510.05381
- Fogg, B. J. (1998). Persuasive computers: Perspectives and research directions. Proceedings of CHI 98, Association for Computing Machinery. https://mari.usc.edu/wesrac/wired/bldg-7_file/Persuasive_Computers.pdf
- Fogg, B. J. (2003, April 6). How to motivate & persuade users [Conference tutorial]. CHI 2003 New Horizons. http://chi2003.org/docs/t35.pdf
- Fogg, B. J. (2005). The functional triad: Computers in persuasive roles. Persuasive technology: Using computers to change what we think and do. Flylib. https://flylib.com/books/en/2.438.1/the_functional_triad_computers_in_persuasive_roles.html
- Gallegos, I. O., Rossi, R. A., Barrow, J., Tanjim, M. M., Kim, S., Dernoncourt, F., Yu, T., Zhang, R., & Ahmed, N. K. (2024). Bias and fairness in large language models: A survey. Computational Linguistics, 50(3), 1097–1179. https://doi.org/10.1162/coli_a_00524
- Garbenis, S., & Kaffemaniene, I. (2025). Developing traits of self-confidence and intrinsic motivation in students with severe special educational needs in physical education lessons. Behavioral Sciences, 15(11), Article 1449. https://doi.org/10.3390/bs15111449
- Gates, B. (2023, November 9). AI is about to completely change how you use computers: And upend the software industry. Gates Notes. https://www.gatesnotes.com/meet-bill/tech-thinking/reader/ai-agents
- Grace, K., Sandkühler, J. F., Stewart, H., Weinstein-Raun, B., Thomas, S., Stein-Perlman, Z., Salvatier, J., Brauner, J., & Korzekwa, R. C. (2025). Thousands of AI authors on the future of AI. Journal of Artificial Intelligence Research, 84, Article 9. https://doi.org/10.1613/jair.1.19087
- Hipólito, I. (2024). The context window fallacy in large language models [Preprint]. OSF Preprints. https://doi.org/10.31235/osf.io/yv8he
- Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y., & Ginsburg, B. (2024, August 6). RULER: What's the Real Context Size of Your Long-Context Language Models? [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2404.06654
- Kokotajlo, D., Alexander, S., Larsen, T., Lifland, E., & Dean, R. (2025, April 3). AI 2027. AI Futures Project. https://ai-2027.com/
- Kotek, H., Dockum, R., & Sun, D. Q. (2023). Gender bias and stereotypes in large language models. Collective Intelligence Conference, Association for Computing Machinery. https://doi.org/10.1145/3582269.3615599
- Kumaran, D., Conmy, A., Barbero, F., Osindero, S., Patraucean, V., & Veličković, P. (2026). How do LLMs compute verbal confidence [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2603.17839
- Kumaran, D., Patraucean, V., Osindero, S., Veličković, P., & Daw, N. (2026). How LLMs detect and correct their own errors: The role of internal confidence signals [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2604.22271
- Laban, P., Schnabel, T., & Neville, J. (2026). LLMs corrupt your documents when you delegate [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2604.15597
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12, 157–173. https://doi.org/10.1162/tacl_a_00638
- MacLellan, E. (2014). How might teachers enable self-confidence? A review study. Educational Review, 66(1), 59–74. https://doi.org/10.1080/00131911.2013.768601
- Maharana, A., Lee, D.-H., Tulyakov, S., Bansal, M., Barbieri, F., & Fang, Y. (2024, February 27). Evaluating Very Long-Term Conversational Memory of LLM Agents [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2402.17753
- Mallen, A. T., Brumley, M., Kharchenko, J., & Belrose, N. (2024). Eliciting latent knowledge from “quirky” language models. Conference on Language Modeling. https://openreview.net/forum?id=nGCMLATBit
- Maynez, J., Narayan, S., Bohnet, B., & McDonald, R. (2020, July). On faithfulness and factuality in abstractive summarization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.173
- METR. (2026, May 8). Task-completion time horizons of frontier AI models. METR. https://metr.org/time-horizons/
- Moon, K., Green, A. E., & Kushlev, K. (2025). Homogenizing effect of large language models (LLMs) on creative diversity: An empirical comparison of human and ChatGPT writing. Computers in Human Behavior: Artificial Humans, 6, Article 100207. https://doi.org/10.1016/j.chbah.2025.100207
- Murphy, G. L., & Medin, D. L. (1985). The role of theories in conceptual coherence. Psychological Review, 92(3), 289-316. https://doi.org/10.1037/0033-295X.92.3.289
- National Research Council. (1994). Self-confidence and performance. Learning, remembering, believing: Enhancing human performance (pp. 173–206). National Academy Press. https://doi.org/10.17226/2303
- Perkins, K. E. (2018, July). The Integrated Model of Self-Confidence: Defining and Operationalizing Self-Confidence in Organizational Settings [Doctoral dissertation, Florida Institute of Technology]. Scholar Commons @ Florida Tech. https://repository.fit.edu/etd/346/
- Sarma, G. P., Bhatt, S. D., Jacob, M., & Steratore, R. (2026). Artificial general intelligence forecasting and scenario analysis: State of the field, methodological gaps, and strategic implications (RR-A4692-1). RAND Corporation. https://doi.org/10.7249/RRA4692-1
- Stankov, L., Lee, J., Luo, W., & Hogan, D. J. (2012). Confidence: A better predictor of academic achievement than self-efficacy, self-concept and anxiety? Learning and Individual Differences, 22(6), 747–758. https://doi.org/10.1016/j.lindif.2012.05.013
- Thinking Machines Lab. (2026, May 11). Interaction models: A scalable approach to human-AI collaboration. https://thinkingmachines.ai/blog/interaction-models/
- Vaswani, A.,, Shazeer, N.,, Parmar, N.,, Uszkoreit, J.,, Jones, L.,, Gomez, A. N.,, Kaiser, Ł.,, & Polosukhin, I. (2017). Attention is all you need [Preprint]. https://doi.org/10.48550/arXiv.1706.03762
- Wang, Q., Fu, Y., Cao, Y., Wang, S., Tian, Z., & Ding, L. (2023, August 25). Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2308.15022
- Wynn, G. (2024). Reformative concept analysis for applied psychology qualitative research. Qualitative Research in Psychology, 21(3), 251-278. https://doi.org/10.1080/14780887.2024.2346851
- Xiong, M., Hu, Z., Lu, X., Li, Y., Fu, J., He, J., & Hooi, B. (2023). Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2306.13063
- Yan, L., Jin, Y., Zhao, L., Martinez-Maldonado, R., Li, X., Guan, X., Guo, W., Han, X., & Gašević, D. (2025, October 19). Agentic AI as undercover teammates: Argumentative knowledge construction in hybrid human-AI collaborative learning [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2512.08933
- Yoshizawa, S., Onzo, A., Nozawa, S., Takano, T., Ishikawa, T., & Mogi, K. (2026). Metacognition of ChatGPT in confidence judgements. Frontiers in Artificial Intelligence, 9, Article 1694192. https://doi.org/10.3389/frai.2026.1694192