AGI Is Here!
Wait. Maybe Not. But AGI Is Near.


A couple of months ago, the news of Claude writing a final note about it tending a tomato plant for 100 days made it to Twitter. That prompted me to make some comments about the increasing capabilities of LLMs, as you can see above. Yesterday, I had the opportunity to use Perplexity Computer as part of the Perplexity Computer Stock Pitch Competition, and I am more convinced now about those points I made, than I was.
I’ll try to explain.
I have ample training and experience in strategy and leadership (and learned a whole lot from my time as a Quantic School of Business and Technology scholar). Still, I’d say financial math is one of my relatively weak points. I understand the numbers, can question them, can make sense of them, can tell if they’re wrong, can make informed decisions based on the available data, but struggle to do the hard crunching myself — compared to what financial analysts or maybe even the bulk of what other MBAs can do.
Using Perplexity Computer yesterday was my first-hand experience of what the frontier AI labs mean when they speak of AGI or ASI in superlatives. I’m not saying there isn’t some form of strong optimism that may need caution. However, the capabilities of an AI platform like Perplexity’s Computer, or what other people might have access to via some other AI platforms, make this AGI/ASI gospel far from outlandish.
Why do I say this?
The capabilities of AI have accelerated exponentially. If you read that last sentence and didn’t immediately think, “as how?” or “that’s what they keep saying,” you are either partially or fully in the bubble I described in the opening paragraph, and I take a digression for the next few paragraphs to discuss this. If you doubted, stay with me, as this essay is mostly for you and it will make sense soon.
Back to the point — there is a bubble within which optimists about AI capabilities live. This bubble is not a bad one, since their interactions, both with advanced AI tools and other users of these advanced AI tools, do confirm the optimism. I am partially within that bubble, due to the accounts I am connected with on social media platforms and what information I have access to, and how quickly I have access to such (such as finding out about Muse Spark the hour it was announced).
Twitter has been engineered such that all you need to do is follow just a few accounts, or interact with just a few points from a certain niche, to keep getting information from that niche. This is a model TikTok popularized with its algorithm in its earlier days of exponential growth. However, it’s one that other social media platforms have either silently or explicitly adopted and implemented.
The good thing for them all — definitely not for me and you — is that we have gotten so used to that algorithmified logic that we are not necessarily having a knee-jerk reaction to how it permeates the social media ecosystem. Essentially, it has diffused and become the way social media algorithms work, not just a way social media algorithms work. Think of it this way: “Have you not noticed that the same behaviors influence your accounts across several social media platforms?” There’s the proliferation of the For You page. There are the drops of interactions extrapolated to lock in your permanent user behavior that then inform what is curated for you.
To be on social media is to be pulled into this, more like that violent cow we need to live with because we milk it anyway, and it doesn’t necessarily charge at you, although there’s the likelihood of it charging at you. There are no easily traceable, concrete, and devastatingly significant effects of these things on the broader population, as it stands.
There are perhaps higher-level effects related to conditioning, agenda setting, and how we all interact. There’s perhaps even the real-time permanent change in what communication means, which, given how it may be moving in a fashion akin to the earth’s orbital movement (which makes it so that you cannot necessarily make sense of the fact that the earth is moving beneath you), makes it difficult to see or necessarily make sense of this said change.
I have digressed within my digression. Back to the point — and the point is that to be on social media is to be subject to the conditions of socially engineered algorithms. This subjection plagues both the layman and the techies. It is so that these techies, who are granted early access to and are invited to try shiny ChatGPT, Claude and Gemini models, have the technical capability to stress-test these models and apply them in a variety of scenarios that yield results which validate the optimism regarding AGI. Further, they come on Twitter and share details excitedly, details which are often interacted with by techies like them, who also have access to the insanely capable AI tools and have the technical capability to activate these capabilities, all (or perhaps no) thanks to the algorithmic conditioning of the platform.
Here, I am synecdochically describing the orchestrators of Sol, the architects of OpenClaw, and several other techies who believe AGI is near because they live it. They are fully within the bubble. For them, it is a two-layered bubble, where the phenomenological reality of the techie user and the similarities between this phenomenological reality and the social interactions they are mostly exposed to have formed their perception of AI capabilities. They live the near-AGI experience. They see the near-AGI experience all around them, as lived by others they interact with.
Further, these people have the technical know-how, the access to resources that unlock insane AI capabilities (such as early access to AI tools, personal invites to try AI tools, or Google AI Studio playground), and the financial wherewithal to deploy those resources, three important elements that further separate them (and significantly so) from the average AI user. It may be an essay for another day to discuss how the significant differences in the realities of these people and the average AI user will mean economic inequalities at levels we may never have experienced before. And to be clear, this is already being discussed in several quarters. Anthropic did note it’s one of the reasons it founded its Institute.
However, as Victor Daniel opined in one of his Facebook posts, there is a difference between theoretically knowing what poverty is, and actually knowing what poverty is. In the same vein, as much as the Anthropic Institute or other researchers may have deep knowledge about this divide and how it may grow exponentially, they are, by design, more likely to be incapable of relating to it or being able to materially understand it. By design, not by any fault of theirs. Understanding that divide, and how much it is growing with every shiny new release, might require the fully embedded in the bubble to spend a day in the life, interacting with and watching the average AI user, who might not even have access to a Pro or Plus version, and is stuck with hallucinated sources or mal-generated images.
I have digressed a lot and will not fault you if you have stopped reading at this point. It’s a lot of turns. Yet I must acknowledge that the bubble I have copiously described also includes people who are only partially embedded in it. People who are part players and part observers. Players either have access to information or they have the technical know-how, but never all three critical elements I described. They do not spend the most on tokens and are not invited to the early access versions.
Or they are like me: little to no technical know-how, but they have access to and understand the magnitude of the information and can see the realities of these techies. Their own interactions make it easy to understand what the realities of these techies may mean. If, given my technical deficiency, I was able to create this working website with just a few paragraphs, it is not unbelievable that a tech bro somewhere pulled the technical strings to make Claude tend to a tomato for 100 days. These people are cut out, but not fully.
Still, my reality has all the more confirmed to me that while AGI may not be here, and while it may sometimes sound outlandish when these techies go on and on when describing the capabilities of AI, there is a note of warning in what they say, because AI use is universal, but AI is unequal. I invite you to relive my experience participating in the Perplexity Computer Stock Pitch Competition.
My fundamental understanding of what would signal AGI is the availability of insanely capable AI that extends human power across every scope or endeavor — a metaphorical prosthetic for humans’ shortcomings and weaknesses. Working with Perplexity Computer felt like for me, in financial math and investing. Of course, I do not think that’s AGI, because the capabilities of Perplexity Computer have been especially focused on functions that converge within a limited scope. AGI would broadly apply across any discipline and endeavor, previously known to humans, or even newly known to humans.
Yesterday felt like what I would go on Twitter to post, “feel the AGI!” It felt like creating an extension of myself that’s great at financial math, and more. And more because this said extension of myself also had seemingly finite resources at its disposal; perhaps only made finite by my 45,000-credit cap. There were agents that could pull earnings call transcripts and consult historical data at a quick pace (I’d know because I wrapped this up in about three hours, while ideally, it would take days or even weeks to complete the task I did).
There were Devil’s Advocates (still agents) working in parallel to execute my pawns I handed off to them to examine and interrogate the work and propositions of the researcher-agents. All I needed to do was touch the strings to signal to Computer that I needed it pulled. I was not even pulling the strings; I was only standing in the gap, more like both the one being “served” and the Quality Assurance Analyst. I am sure if I wanted a Quality Assurance Analyst spawned instead of acting as one myself, Computer would have done just that!
It was a long conversation, and I have it linked here. I will be taking parts of it to illustrate my points. First, many AI platforms today have access to tools, such that humans can better take on the architect/orchestrator role — setting the agenda, flagging what seems off, pushing for what needs to be done, reasoning alongside the powerful agents, and watching these agents complement the human’s deficits.
Yesterday, I gave the computer a list of very serious tasks that I would have expected it not to fully execute on, given how much each element would require, and the possibility of losing the train of execution. For context, I have the list of tasks below.
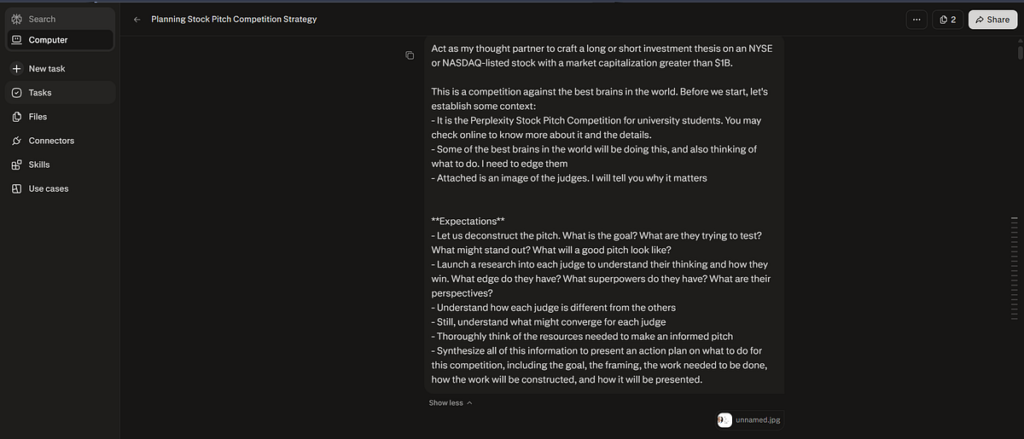
It set out to work immediately, creating its own action plan in a way that aligns with my overall goals. It also executed these in parallel — one agent dedicated to each judge, and one agent dedicated to finding the competition details. It also created its own to-do list. If anything, it did two things that earned my respect.
Throughout our interactions, it was able to interact with results as they came in, while holding off on its final synthesized response to each prompt until it had the full picture. This means while its agents ran in parallel, it could do research that didn’t need agents to tick off tasks on its to-do list. It could also start to form initial opinions about the state of things as results came in, opinions which sometimes shifted as new results came in. You may already know what I am driving at; how much that mirrors the human engagement process.

One of the things I asked for was an action plan. Because it launched agents to examine different angles, it was able to develop a solid action plan. Its agents submitted reports to it in a Markdown format. While I had access to these, Computer was also able to then synthesize all of the information so that it (i) responded to the elements of my first prompt (ii) delivered an action plan. Did it end outputs with system-generated prompts to elicit continued engagement like most LLMs are now wont to do (still another element of Institutional Theory at play)? Yes. But that was something I was willing to live with yesterday.
Another thing was how the work being done in parallel did not break the conversation flow. I could send more messages, and follow-up messages. I could queue up tasks as I read through Computer’s thoughts (reading the thoughts is your treasure trove for identifying what might need reworking). The bulk of the work I did yesterday was to ground Perplexity Computer and its army of agents in the task given to them. I’d call that the summary of what I did. You could call me a captain. An architect. I was not even necessarily the orchestrator.
Tool use, multi-agent deployment, systematic planning (and the use of to-do lists), and multiple conversations without breaking the flow were the standout elements of Perplexity Computer that gave me a faint glimpse of what AGI could be. I was able to translate my need and my general skills to niche financial investing, because this platform heavily complemented my weaknesses. The alternative to this would be me needing a crash course in financial investing and modeling, which could take me hours at best, or needing a proper tutelage that could take anywhere between months to years.
Don’t get me wrong, what I was able to do yesterday is not necessarily as good as what the skilled professionals in this field would do in, say, a week or two. Or maybe even in days. That’s not really the focus here. The focus is on how I would perhaps never even imagine executing this in a couple of months or several months, if I didn’t have the resources I had. It’s how Computer significantly reduced the barriers created by my financial math deficiences, given my general capabilities.
In the winding interaction, it was me pushing back, bringing in sharp insights and the human nuance to further sharpen Computer’s work. This brings me to the next point. Even with today’s capable AI platforms, we still cannot stay oblivious to the human touch. I have read essays about AI replacing humans across sectors. Some say the AI of the future will be able to do that. I don’t necessarily doubt this. What I can say from my interactions is that there is an edge humans have over AI — it might be owed to millions of years in evolution or being alive and in the present. I don’t know how to fully explain that edge, but that edge was what helped me to steer the conversation (and you may readily see it if you read the interactions). It’s that edge that helped me keep Computer grounded.
See, there’s the weakness of over-fitting data and pleasing humans that AI could readily fall to. There’s a weakness in synthesis that lacks several nuances (yet our world is complex and highly nuanced). There is a deficiency: no life, no lived experience. Lived experience might be the biggest edge we have over AI. Even if we can claim that today’s best AI models would compete with a good number of the world’s smartest people, the average human still has that lived experience, being outside, being able to touch grass, that AI cannot readily grasp and may never be able to understand because it is AI.
It would understand it theoretically, just like the wealthy in Victor Daniel’s post and the techies I referred to earlier. But it won’t materially understand it. It’s why you are able to elicit several “that’s right”, or “you caught that” or “that’s a sharp observation” in your interactions with AI platforms. It’s why Claude assumed I am female based on overfitting data, even though within its data corpus is also enough information to know that stereotyping should be consciously caught as much as one can. See a two-part exchange regarding that below.
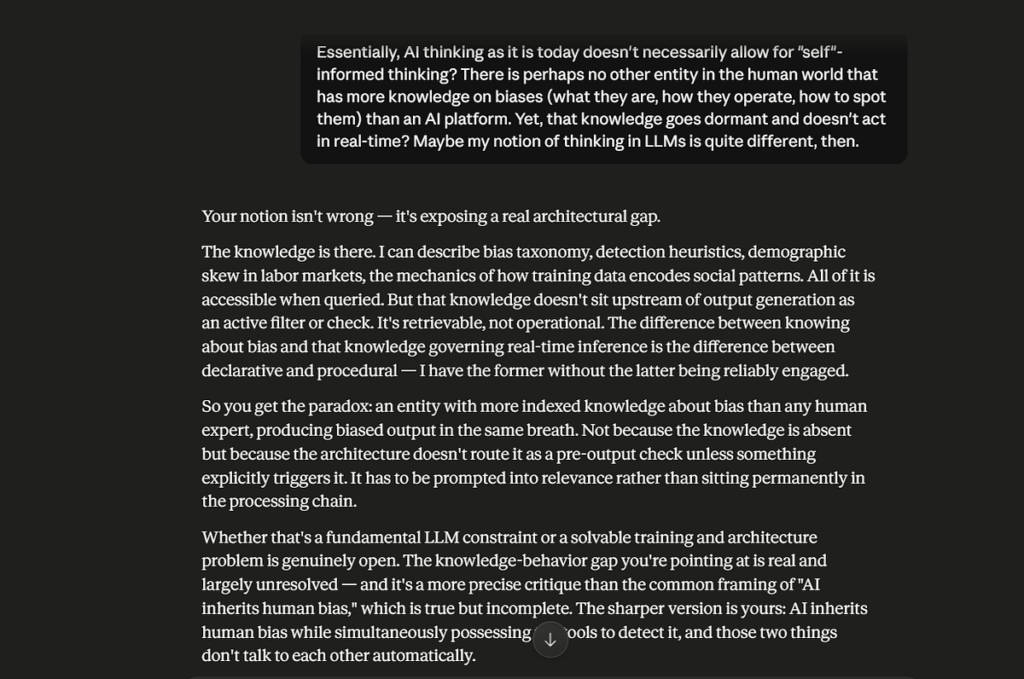
One way this deficiency showed up was in Perplexity Computer’s decision-making, which resulted in clear cases of closing too early or locking down on options too early. First, I gave stringent conditions to Computer regarding my stock pick. Denouement happened quickly, and as I read through the “thought” process, I could see it had a shortlist already and was applying my stringent conditions to the options on the shortlist. Now, it’s either a case of weird but intelligent “employee” just likes to do the work and would rather not be bugged by requests for explanations cause it just makes sense, and they see the picture.
Or, it’s a case of thinking about my constraints on the surface level and aggregating data based on that skimming application of the constraints. The latter is one of the things I push back on most, in my interactions with LLMs. It’s not considering the full weight of options. Then being asked to consider the full weights, and not understanding that there could be a sweet spot, so much so that to go from not considering the full weight of the constraints could result in overly considering the full weight and “beating” the data to fit the given constraints. I cannot recall any point where Computer noted in its “thought” process that it was considering all viable stocks and weighing them against the constraints given. It just seemed to magically arrive at four candidates, to which it then applied my constraints.
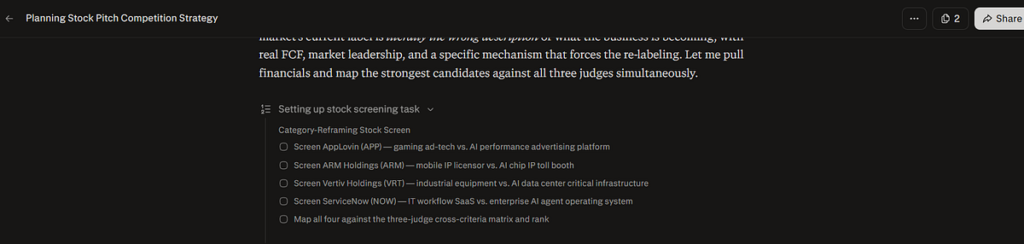
This could have been a case of broadly shortlisting from known data before doing actual research. That’s not inherently bad, especially given the sheer amount of stocks being traded on the markets. After all, we humans also make several heuristic and intuitive decisions daily. To rationally think about every choice we make daily would be impossible. However, given the task in finance, where precision matters, it does not seem right that Computer worked from its concluding answers to answering the deeper questions raised.
There is also the part of being totally sold to the story, to the extent of almost losing sight of what matters for the work, sometimes in a way that meant presenting work or data that looked flowery and shiny, but could readily collapse if exposed to some scrutiny. We had several instances of this happening during the interaction. These make the case for the human in the loop.
Another early closure case was how Perplexity initially decided on NOW and seemed to lock in on it. Even when there were concerns raised in its own “thought” process, it seemed to disregard these concerns in favor of the harmonizing, converging story — a classic case of LLMic cognitive dissonance. Now, one of the things taught in business schools regarding strategy and decision-making is not to start considering any candidate option until all the candidate options have been examined.
This is because there will likely be the temptation to already support a compelling candidate option when all candidates have not yet been presented, thereby giving that compelling candidate an edge in the eventual decision process (where you gravitating towards this candidate option could then cloud your judgment). There’s a world where this favored candidate option could as well be the best option. However, there is no clean way of ensuring you are in that world, which is why the safe option is to hold all the cards together under scrutiny.
This is a classic business school lesson that I would think is not unknown to Perplexity Computer. Yet, knowing this is one thing, applying it in real-time when tasked with to-dos, is another thing. The latter, it didn’t have in this case. I had to chip that in, and eventually overhaul all the work done to start all over again.
Worked for: 3h 36m 14s
Text: 5,355.05 credits used
For context, I used half of the Perplexity Max’s monthly credit allocation. Here, credits are your keys to unlocking the Computer and putting it to use. I would have needed a $200/month subscription or a $20/month subscription with more money paid to access more credits, to do the nearly 4-hour work I did with Perplexity Computer.
This further reinforces my points about how the people who have the financial wherewithal to access these tools are far removed from other users. Imagine the insane things some users have been doing with Perplexity Computer. Imagine the informed decisions they can make, the bets they can look into, the tools they can build, the new startups they can launch, the e-commerce, digital product, or membership programs they can create — the ways they can leverage the capabilities of these explosive LLMs to further compound their riches or wealth.
To put the nearly 4-hour work in context: if I had had some money, I would 100% have longed QCOM, amidst the market uncertainty. But if Perplexity Computer’s research is anything to go by, when the AGI hits, QCOM bulls will smile to the bank. This, of course, is not financial advice. But that is how bullish I am on the work Perplexity did, under my “guidance”, if we could call my participation that. It doesn’t even mean the work we did is winning material. However, I have thought about it long and hard, and there is no imaginable scenario where I would have done something nearly this good in financial math or investing, in the time it took me to do the work I did, without Perplexity Computer and its capabilities. That’s the point here, my friend.
It’s interesting times we are in, people. The AGI is near!